This story was told before at a number of conferences, e.g. at NDC Oslo:
You can find other slides and videos here.
Finally, I found some time to write a blog post about it. I added additional links where appropriate and try to attribute sources as well as possible. If you find an error or have a comment please contact me (see at the bottom).
TLDR
High workload leads to increasing waiting times and is detrimental to your project’s success. Nevertheless, teams often find themselves in high workload situations, showing symptoms of overload and being too busy to implement the necessary changes or adopt the state-of-the-art tools to get the upper hand.
This is a story of how you can apply the Three Ways of DevOps to get out of a state referred to as quicksand (The more you fight it, the more it pulls you in).
I not only write about queuing theory and capacity management, but also about DevOps strategies to cope with high utilization and how to start a virtuous circle.
Key takeaways are:
- High workload leads to increasing waiting times
- Crisis situations are opportunities for change and often it takes fresh eyes or at least courage to see problems
- Get out of the quicksand with DevOps:
How did I end up here?
My name is Roman Pickl and for the last year and a half I’ve been a technical project manager at Elektrobit, which is an automotive software supplier. Before that I was CTO of a medium sized company called Fluidtime, but also a process manager at the Austrian parcel service, which also deals with some kind of continuous delivery, I guess…
I have a background in software engineering, business administration and computer & electronics engineering. CI/CD/DevOps is the sweet spot for me, as I really love how the things I learned in my Production Management and Operations Research courses are nowadays applied in the IT domain.
In September 2018 I was speaking at the DevOpsDays in Cairo and Andrew Clay Shafer, showed a slide with the following quote during his keynote:
I don’t have time to learn new things because I’m too busy getting things done!
— least productive person in the world
During that time I was also working on this talk and it really resonated with me, as I was reading Tom DeMarco’s 2002 book Slack, which also states that we are all too busy and this not only kills our efficiency but also our effectiveness.
Being effective and / or being efficient
Daniel Scocco provides a good explanation and example of the difference between being effective and being efficient: https://www.dailyblogtips.com/effective-vs-efficient-difference/
Being effective is about doing the right things, while being efficient is about doing the things in the right manner.
- You are efficient when you do something with minimum waste
- You are effective when you’re doing the right something
It’s possible to be one without the other, it is also possible to be both or neither
Example: flat tire
Based on the example of Daniel Scocco: If your car breaks down and you have a flat tire, and you start cleaning the car or change the wrong tire, you could be very efficient at this task but you are definitely not effective in fixing your car. On the other hand, if you change the right tire, but it takes you 2 hours, because you don’t know exactly how it works and it takes you multiple attempts, you are effective, but not very efficient.
So we want to be both, but often we are neither.
In his book, DeMarco also cites evolutionary biologist Ronald Fisher:
The more highly adapted (i.e. efficient) an organism becomes, the less adaptable it is to any new change.
— Fisher’s fundamental theorem
So we need to find the right balance and not over optimize.
I my career I found myself in a situation similar to the following multiple times…
An overloaded team
So I’m part of an ops or dev team of three and the workload is not evenly distributed.
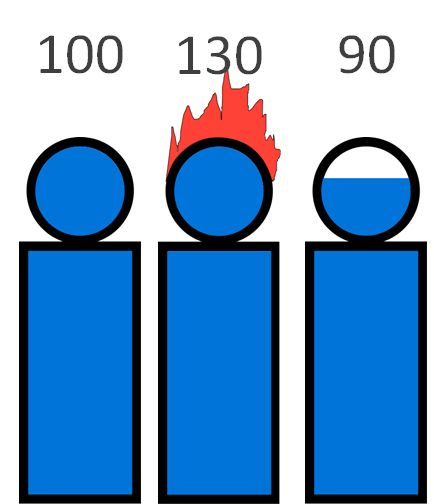
An overloaded team
One, often times the person with the most experience, skipping or having lunch breaks at their desk, working on weekends, being the bottleneck and having their hair on fire.
And maybe one, more junior, person with some slack, but no one of the others has time to show them new stuff or holding on their dear tasks.
So we experience an overload situation and also show symptoms of overload like:
- decreased team morale
- working when sick
- being sick all the time
- unhealthy tasks queue
- imbalanced metrics,
- and so on
It hurts again and again
And then the following discussions are getting more frequent:
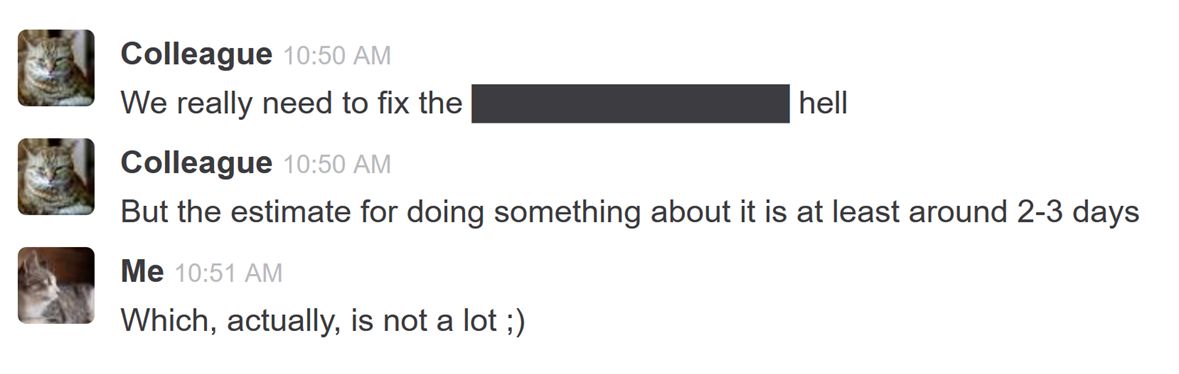
chat discussion about fixing technical debt
I’ve changed the pictures here, but other than that it’s more or less a screenshot of the discussions we had.
So my colleague says something like:
We really need to fix the … hell.
But you know, this will take some time.
The estimate for doing something about it is at least around 2-3 days
And I’m like
2-3 days… that’s actually not that much…
And it hurts again and again
We really need to.. use a static code analyzer, improve the deployment pipeline, introduce a better debugger, etc. But it never seems to happen.
No thanks, too busy
And I feel like:
source unknown
Busy cavemen
I know that there is a better way of doing stuff, I talked with friends with way more experience about it, I have seen it at conferences but we are just too busy.
In my talks I ask the audience whether they can relate to this situation by raising a hand and based on the results, it seems to be a common phenomenon.
What your manager thinks should be done
So I go to my manager and ask him/her for support in the DevOps, testing, … domain and the following dialog takes place:
Manager: Yeah you know, I don’t know if we should look for support in this area. Just do some redistribution of work. And it will certainly take time to find someone. I’m not even sure if we were be able to utilize that person up to 100%. But I’ll talk to xyz in the other department there is a project currently on hold and one of those people may help us with these missing 20%.

The manager's proposal
3 persons working. All at 100% of their normal working time. Instead of a 4th person working 20%, the manager will ask another manager if one of their team members, which already is working on 5 projects, but one of them on hold, can provide the ‘missing’ 20%.
Me: That’s not going to work. Individual knowledge workers are not freely exchangeable / replaceable (Tom DeMarco calls this the myth of the fungible resource in the book Slack) and you don’t want to do that anyway. Utilization is not a good proxy for productivity (according to DeMarco).
Manager: What? What are you talking about?
Me: OK. Let’s talk about queuing theory.
Queuing theory
So when preparing for this talk I remembered that queuing theory and operations research is very interesting but also quite hard to understand in its details.
This is discussed at various places already in the context of IT e.g. The Phoenix Project, in Making Work Visible, here, here and even more detailed in More with LeSS and in The Principles of Product Development Flow: Second Generation Lean Product Development.
There are different type of queues and models but let’s look at the simplest case. In a G/G/1 single server queue inter arrival times have a general (arbitrary) distribution and service times also have a (different) general distribution.
You could imagine a single cashier with customers coming in at different times / intervals with different number of articles in their shopping basket.
The lead time (time to go through the whole process) of a system is heavily influenced by the service time, the utilization of the actor and the variation in the process (task variability, interarrival variation).
This is also what the Kingman Equation / approximation tells us:
$$ E(W_q) \approx \left( \frac{\rho}{1-\rho} \right) \left( \frac{c_a^2+c_s^2}{2}\right) \tau $$
As described in the Wikipedia article (with some additional notes concerning the example): ‘‘τ’’ is the mean service time (the time it takes the cashier to handle one customer) (i.e. ‘‘μ’' = 1/‘‘τ’’ is the service rate; which denotes the rate at which customers are being served in a system, if it takes the cashier an average service time of 0.5 minutes to handle a customer, the cashier would have an average service rate of 2 customers per minute)
‘‘λ’’ is the mean arrival rate (of the customers)
‘‘ρ’' = ‘‘λ’'/‘‘μ’’ is the utilization (of the cashier) ,
‘‘ca’’ is the coefficient of variation for arrivals (that is the standard deviation of arrival times divided by the mean arrival time) and
‘‘cs’’ is the coefficient of variation for service times.
If we assume that software development / operations is a process with high variability, i.e. with a decent amount of task variability and interarrival time of theses tasks, then wait time is related to the percentage of time busy by percentage of time idle.
If a resource is fifty percent busy, then it’s fifty percent idle. The wait time is fifty percent divided by fifty percent; so one unit of time. So on average a task would wait in the queue for e.g. one hour before work starts. With ninety percent utilization it would be in waiting state for 9 times longer.
Note that this graph gets steeper with higher variance and flatter with lower variance, being a flat line in a perfect world:

Wait Time (Queue Size) as function of utilization
So there is an inherent conflict between service quality and capacity management with things deteriorating heavily at ~70-80 percent, depending on the variability of the process of course.
If you want to play around with this: Troy Magennis has created a nice interactive calculator which is available at: https://observablehq.com/@troymagennis/how-does-utilization-impact-lead-time-of-work
A similar idea is Little’s law, which shows a relationship between average lead time, average work in process (WiP) and average throughput.
Little’s Law:
$$ Avg. Lead Time = \frac{Avg. WiP} {Avg. Throughput} $$
But there are some important assumptions to it , you can find more in the presentation from Daniel Vacanti here Little’s (F)law.
The important takeaway is that you should focus on throughput rather than utilization.
And if you reach high utilization levels all your work is just piling up and everyone gets very nervous and calls for status meetings which adds additional work.
So this escalates quickly. You then reach a state that Mario Kleinsasser in a GitOps presentation at the Vienna-DevOps-Security meetup referred to as quicksand. (This talk was not recorded, but you can find a similar one here: https://www.youtube.com/watch?v=Ocmx7nifh2I&t=403)
Feels like quicksand
It feels like quicksand, the more you fight it, the more it pulls you in.
Each time you try to put your leg out, it sucks you in again.
But don’t panic.
This is similar to what Shane Falco (Keanu Reeves) describes in movie “The Replacements” from 2000.
You’re playing and you think everything is going fine. Then one thing goes wrong. And then another. And another. You try to fight back, but the harder you fight, the deeper you sink. Until you can’t move… you can’t breathe… because you’re in over your head. Like quicksand.
— Shane Falco #16 (Keanu Reeves)
Again, a considerable number of hands are raised if I ask the audience whether they can relate to that feeling.
I really liked this metaphor and so I googled how to get out of quicksand and I was not disappointed (https://www.eaglecreek.com/blog/how-escape-quicksand).
- Make yourself as light as possible—toss your bag, jacket, and shoes. – so that could refer to reduce Work in Process
- Try to take a few steps backwards. – e.g. to analyze the situation
- Keep your arms up and out of the quicksand. – so make sure that you are still able to act
- Try to reach for a branch or person’s hand to pull yourself out, but make sure you don’t pull them in
- Take deep breaths.
- Move slowly and deliberately.
So I go to my manager again and tell him, you know what, we really need more people …
What you think should be done: hire more people
Slack is the missing ingredient required for all change
— Tom DeMarco’s 2002 book Slack

What you think should be done: hire more people
And all of them should only be “utilized” up to 80% so that they can invest roughly a day per week to
- Spur innovation
- Rethink
- Practice new ways
- Master new skills
- Improve efficiency.
Because that’s how it is or has been done at 3M with their 15%-time and Google with their 20%-time.
At Google Site Reliability Engineer Principle number two says, that people must have time to make tomorrow better than today (https://landing.google.com/sre/workbook/chapters/team-lifecycles/). They also have a hard limit on the percentage of time spend on toil, i.e. “Toil is the kind of work tied to running a production service that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows” (https://landing.google.com/sre/sre-book/chapters/eliminating-toil/) as opposed to engineering that produces lasting value. It is set to 50% (https://landing.google.com/sre/workbook/chapters/how-sre-relates/).
Note that Agile Methodologies like Scrum (sustainable pace, iterations) and Kanban (WiP limits) also have ideas to limit work in process and working hours.
So after all this research and listing all the pros I have persuaded my manager, but it is too late.
What actually happened
People under time pressure don’t think faster
— Tim Lister in Tom DeMarco’s 2002 book Slack

What happened
What actually happened is, that we got even more to do and spent considerable time interviewing. It was quite unsure, whether we even would find someone…
So that the colleague, you know they one with the hair on fire, could not bear it anymore and quit.
Now me and the other team member also are under heavy pressure. And people under time pressure don’t think faster.
But at least we found a very skilled professional, who starts today. Could be
YOU
And given that you have just joined the team, you usually cannot jump right in and have some slack, at least in the beginning.
Congratulations you have joined a team in an existential crisis.
It sometimes takes a crisis and fresh eyes
But that’s not necessarily a bad thing.

This if fine - meme
In the A Seat at the Table Book, Mark Schwartz writes that:
Transformational projects occur when the amount of debt has become too much to bear
Often organizations need to experience an existential crisis before they really take continuous improvement seriously. That’s also what Jez Humble mentions during this talk: https://www.youtube.com/watch?v=2zYxWEZ0gYg&feature=youtu.be&t=3003. and what John Cutler answered when I asked him about being too busy to change.
One reason could be that a 10% change (e.g. working overtime) is not enough anymore, now a 50%+ improvement is needed, often an engineering solution (This is also discussed in Gunter Dueck’s book Schwarmdumm (German) also here https://youtu.be/rc37ov1iVFQ?t=657)
If you can establish
- A sense of urgency (We have to change how we work)
- A save environment for failure (Things that were already late, will shift, but we really need to try something new)
- And have the courage to question the status quo (which is easier if you are new)
Crisis are chances and opportunities to change things. Or as Winston Churchill put it:
Never let a good crisis go to waste
Example: iOS App deployment
I’m getting a little ahead of myself here, but a little example.
4 years ago: After the most senior member of the team quit, I supported our ops team and asked how we deploy our iOS Apps:
So they told me:
- For each of the 5 Apps do:
- Checkout the code on your local PC
- Make sure you have the right Xcode version installed
- Do these 3 manual changes
- Select the right signing certificates
- Compile
- Upload to App Store
- Enter / update all the relevant metadata
- Wait for apple to review the software
So this takes roughly 1 day.
“But what if, the developers/tester find an error?” I asked.
“We have to start over, and as this is so painful, we release very seldom and asked the team for less releases which are tested better.”
“Sorry, but I won’t do it that way. It is 2015 (at least back then) and there has to be a better way to do that. Maybe that was a good solution in the past, but let’s check.”, I said.
So being fortunate 1 year earlier fastlane, was released, which among others helps to automate the release process of Apps.
So we setup fastlane with Jenkins in a way that, with the click of a button and waiting 20 minutes (and of course for the apple review after that) everything was done.
This took us roughly a week to get a first version up and running. And ever since, releasing iOS and Android Apps (that’s the nice thing) was a none event and we did it more frequently with the push of a button.
It also now was self service, so the development team, tester or project manager could do it themselves and did not have to wait for the ops team.
So it really takes someone like you who questions the status quo.
But where to start?
Quantify the work: Activity Accounting
I think first you should quantify the work. So what I like to do is something called activity accounting.
Where you allocate costs to the activities the team is performing to uncover non-value work.
So you can do this based on your time sheets or a look at your task board.

Quantify the work in your team
But you should not only watch out for categories like: Unplanned work and rework, remediating security issues, working on defects identified by end users, customer support work. But also things that you don’t do, or do very infrequently (e.g. updates, releases, retrospectives) or multitasking which could mean that people are waiting for feedback (e.g. due to long build times, or other people not being available).
As a side note: What I also like to do and what really helped is making the things your team is currently working on visible. So in my last company we put up a monitor in front of our desks with our Kanban board and everyone could see what we were currently working on. This reduced the number of interruptions (are you already working on “…"), and also helped to show that we had a lot of things to do and if priorities differed, then people, after looking at the tasks in front of theirs, knew whom to talk to before bugging us.
So according to these numbers from the 2018 State of DevOps report:

Time spent in different categories by group
DORA - Accelerate: State of DevOps 2018: Strategies for a New Economy
the low group, spends 15% on customer support and 20% on defects identified by the end users: so this sounds like a quality or at least documentation problem. What we also see is that low performers only spend 30% of their time on new work as opposed to 50% in the elite group.
So now you know what you are spending your time on and you should set goals based on benchmarks, but what takes so long?
Measure
There is a saying that,
What gets measured gets managed
So you should measure flow time e.g. lead time and cycle time for the features you deliver.
- Lead time measures the time elapsed between “order” and delivery, thus it measures your “production” process from your customer’s perspective.
- Cycle time starts when the actual work begins on the task and ends when it is ready for delivery.
How long does it spend waiting, in testing, on the build server, for hand offs, waiting to be released?
You should also measure the frequency of deployments and your mean time to restore services.
There are additional measures that you could take into account like:
- Bug lead time
- Code lead time
- Patch lead time
- Change success rate
I think it is important to get a rough indication and order of magnitude first, rather than trying to measure it with a stopwatch.
Work in Process (WiP) is a leading indicator, the more WiP is in the pipeline the longer things tend to take to complete (see Little’s law). You can also have a look at aging reports e.g. look at tickets that did not move 30 days or demand / ticket inflow.
On the other hand, we want to increase throughput So what is the biggest bottleneck?
Can we fix it?
Can we bring the pain forward?
Ask why 5 times and investigate the “root causes” (after reading https://www.kitchensoap.com/2012/02/10/each-necessary-but-only-jointly-sufficient/ contributing causes might be the better word) or constraints. Sometimes the fixes are quite easy, once you know the problem.
For a deep dive into DevOps metrics and statistics, and how to do it right, read https://dl.acm.org/doi/10.1145/3159169 written by Nicole Forsgren Phd and Mik Kersten as well as Accelerate: The Science of Lean Software and Devops: Building and Scaling High Performing Technology Organizations written by Nicole Forsgren, Jez Humble and Gene Kim
Example

xkcd - Compiling
I once worked in a project were the full cycle of building and testing took 26 hours. So imagine you do something today, and you don’t get feedback tomorrow, but the day after. Releasing was a manual process which took me as a project manager 1 hour of my time.
If your build cycle takes 26 hours and releasing manually takes 1 hour, start fixing your build cycle first, even if that means that you may have to do the manual process more often in the beginning, get a very good understanding of it and then automate the manual process in the next step.
We used Jenkins back then so I had a look at the console log. Being new to the team and not really having a lot of context I found out that, well I don’t really could tell anything because not all of the entries had timestamps. I installed the timestamper plug-in on Jenkins and now was able to assess which steps in the console took how much time and having a look at the resource manager during these steps of the build, I found that the build was disk bound so we had an I/O problem.
Being fortunate again there was a very small SSD in the build PC, which really was a desktop PC back then, which I used to run an experiment. So I took one of these jobs and moved it from the normal hard disk to the SSD and it was an immediate 36 percent improvement. I went to my manager and told him that these is the cheapest 300 € to spend on speeding things up. And we did.
Tobias Geyer tells a similar story here, which also helped me get this SSD: https://tobiasgeyer.wordpress.com/2013/07/04/improving-jenkins-execution-times-by-common-sense/
Lightweight Capacity Management
When you are in an overload situation there is a tendency to do more planning and more status meetings, but rather you should accept the uncertainty and appreciate flexibility of software development. There is a decreasing marginal utility of each hour spent planning. According to Gary Gruver every hour spent planning is an hour not delivering as the people doing these tasks often overlap. This is discussed here: “A Practical Approach to Large Scale Agile Development” - Gary Gruver at Spark 2013
Side Note: You could also say that every hour spent in a status meeting is an hour not programming. There are also solutions for that. For example: if you have an incident or a very high priority program with a priority issue it may make sense to have a wiki page (or a Google doc) updated every hour instead of calling fifteen people into status meeting three times a day. Read more about this in the Site Reliability Engineering book.
You should really come up with a light weight capacity planning approach. So Gary Gruver, in his book A Practical Approach to Large-Scale Agile Development, says that since their transformation they rank their initiatives and do high-level estimates for each effected component. Then they sum the engineering months they have available and just have a cut off and do the things with the highest priority. They then do the more detailed planning only using a just-in-time approach. It’s also important that you prioritize these things and that there is only one most important thing. People should know what the most important thing is. You could use cost of delay for ranking these initiatives. So ask: “what would it cost us if we don’t do this today”. Maybe you find out some things do not really have a big benefit or a big cost of delay attached to it. If you want to know more, go watch Principles of Lean Product Management by Jez Humble now.
So less is more and this is also something that you should take into account when looking at your work items.
Less is more
So you should reduce your work in process and your batch size. We saw that in Little’s Law .
So stop starting and start finishing.
I think it is very interesting that in all or most of the Agile methodologies there are WiP limits included. For example in Kanban you have WiP limits on your board. In Scrum you have a sprint scope which also limits the work in process.
This will also decrease context switching. It will increase focus. It potentially reduces your cycle time. You will get faster feedback. Usually quality takes time so according to Principles of Lean Product Management by Jez Humble a daring strategy is to reduce quantity.
So say no to additional work or at least postpone it.
Having a look at the equations from before we also see that you should try to reduce variability and increase predictability.
Side node: If you are working on a innovative project, or do a MVP (Minimum Viable Product) prototype you might rather embrace variability and discovery instead.
For example
- reduce the number of platforms you’re working if this is possible
- kill zombie projects or
- maintain less versions and branches, maybe think about trunk based development
- really fix the causes of the problems and not only the symptoms
You should really do less. Some studies show that 50% to 2/3 of new features are never used, do not meet business intent or improve a key metric. This is discussed in Jez Humble’s Book Lean Enterprise and in the following Ronny Kohavi presentation. While this is a strong case for experimenting, it also should make you think how important the feature you are working on really is.
Doing less, at the same time, and working in smaller batches also helps with triage work. If something goes wrong, fewer changes need to be investigated if you look for the source of the problem.
In my last company we set up a CI/CD platform using Jenkins. And if you automate everything you come to the point, where it doesn’t really make a difference, at least on the happy path, who presses the button to release software. So it changed from a matter of having time and the necessary skill, to a matter of permission. Switching to jenkinsfiles and infrastructure as code also had the benefit of developers creating their own CI/CD scripts based on the existing ones or create pull requests, where in the past everyone was rather unwilling to set up their own Jenkins jobs or afraid to break something, because now everything was in version control.
So automate, but first try to eliminate
Automate the right things
At some conferences I hear that people should automate ALL the things and I think that is the wrong approach.
I think you should make time to create automation. Get management support if possible! Sometimes this may also mean to ignore or shift your current work items for some time. So rather ask for forgiveness than for permission.
I also think that documenting the process and making it repeatable is the first step to automation. If you see a long list of steps that some people have do to achieve something then maybe it’s a good candidate for automating this task. So only then you should automate, but first you should eliminate.
As Gary Gruver says in “A Practical Approach to Large Scale Agile Development” at Spark 2013: Automate, eliminate or engineer out the drivers that are not key to your value proposition
- New and unique work (e.g. new features)– hard to automate,
- Triage work – automate for consistency which leads to fewer errors. As mentioned before, working in smaller batches also helps here.
- Repetitive work – reduce or automate, which speeds up the feedback loop and let people focus on new and unique work.
Fix the biggest bottleneck first, everything else may make things worse and accumulate backlog. In my 26-hour-build-time example, for me personally it would have been the easiest thing to automate the one manual task I needed to do because I really did not like it and just just take the 26 hour build process for granted. By improving build times, I even made it worse for me in the first step, but I removed / shifted the bottleneck and automated this step next.
Sometimes your biggest bottleneck may not even be a technical problem, but rather you have to find the right person or make sure they are not overloaded.
What i also liked about our automation and measurement effort is, that we could sometimes reach win-win-win situations or fixing a “root cause” fixed multiple problems.
For example: We noticed, that our end2end tests ran rather slow, so measuring them in detail revealed that, we had a performance issue / memory leak. Fixing this did not only make our test run faster, but also helped us debugging faster, and also our customers noticed a considerable improvement.
Left-Over principle
There are different approaches to automation. Some interesting ones are discussed in the great book The Practice of Cloud System Administration.
For example the Left over principle – automate as much as possible, humans do what is left.
This view makes the unrealistic assumption that people are infinitely versatile and adaptable and have no capability limitations. But it is still helpful as it provides guidance based on the difficulty of the task as well as its frequency of conducting it.

Left-Over principle
- So you start to eliminate.
- the rare and easy stuff you can do manually
- the easy and frequent stuff you should automate
- the frequent and difficult stuff you should look for an open source solution or a product you could acquire
- the difficult, rare stuff you create tools or document
- the very rare and very difficult stuff you hire for e.g. find a consultant to do that.
There are also other approaches discussed in The Practice of Cloud System Administration:
- Compensatory principle – split work between human / machine depending on which one is better at which task
- Complimentary principle – improve long-term health of the combined system
So automation is not a silver bullet solution and a word of caution is necessary.
A word of caution - The paradox of automation
When the new automation is in place, there is less total work to be done by humans, but what is left is harder (Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations, Slack).
This is also depicted in the J-Curve of Transformation from the 2018 State of Devops Report.
J-Curve of transformation
DORA - Accelerate: State of DevOps 2018: Strategies for a New Economy
It says that your team begins the transformation initiative and they identify quick wins and everyone is happy at first. Then you find out that if you automate this process then you have increased test requirements or suddenly your manual processes are the bottleneck and you cannot really scale them. You are blocked by technical debt and really need relentless improvement, refactoring and innovation to reach this state of excellence. This requires spare capacity and slack i.e. you need to invest to be fast and think of improvement activities as just regular work.
So for example if you use fastlane to deploy iOS Apps and it fails, then it takes at least a day to understand signing iOS Apps again.
Virtuous circle
So we freed ourselves from quicksand, which as described is a vicious circle, that pulls us in the harder we try to resist. As Jez Humble puts it: If you are not constantly working to improve, then by default, you are gradually getting worse. Like in the second law of thermodynamics, where entropy just increases over time.
But what’s next? What we want to establish is a virtuous circle: A recurring cycle of events, the result of each one being to increase the beneficial effect of the next.
So we need to establish a culture of learning and improvements that compound. Jez Humble says Lean works by investing in removing waste so that you can increase throughput.
Prioritize improvements that will do the most to improve flow, Start with the bottleneck / biggest source of waste, fix it, identify the next bottleneck, rinse and repeat.
And that is what they also discuss in the Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations book:
Improving your software delivery effectiveness will improve your ability to work in small batches and incorporate customer feedback along the way Lean product management practices positively impact software delivery performance, stimulate a generative culture, and decrease burnout […] software delivery performance drives Lean product management practices […] it becomes a reciprocal model or, colloquially, a virtuous cycle
And also in the SRE workbook where they say that:
Eliminating one bottleneck in a system often highlights another one. As each change cycle is completed the resulting improvements, standardization, and automation free up engineering time. Engineering teams now have the space to more closely examine their systems and identify more pain points, triggering the next cycle of change.
But this may be a complex problem (as discussed in the Cynefin framework), so you may not really know where to start, just what you want to achieve.
Improvement Kata
One experimental approach for product development and process improvement is the Improvement Kata by Mike Rother.

Improvement Kata
It describes the following process:
- You get the direction or challenge (e.g. we want at least 2 full build/test cycles per day)
- You grasp the current condition
- You establish your next target condition
- Conduct experiments to get there
then start again.
Prioritization of Improvements
Another tool which is discussed in The Practice of Cloud System Administration and can help is to collect improvement ideas and prioritize them by ease of implementation and impact.

Prioritization of improvements
It may be obvious that you should start with the easy, small high impact change before the hard, high impact ones, but some companies / teams are still waiting for the grand rewrite / high impact change which may never happen because it is that hard.
Virtuous Circle
So again, we want to achieve this virtuous circle so that Software delivery performance drives Lean product management and Lean product management drives software delivery performance

Virtuous circle
Based on Virtuous Circle of CI/CD in The Site Reliability Workbook
- So you do more release / test automation improvements.
- This means you can do faster releases and have more time for new work.
- Which means you can have more frequent releases,
- fewer changes per release, lower lead time,
- fewer bugs per release, faster feedback, higher confidence,
- which results in more time to automate, decreased burnout, higher job satisfaction
- and off it goes.
So speed up this feedback loop, reduce waiting times and get results faster.
How it ended up working:
So taking this into account, we went on a journey of roughly 6 months to one year.
We really spent 20% or roughly 1 day a week to improve something. This may not have been the fix to the bottleneck in each and every case, but if not at least it made the bottleneck more obvious.
- We created self service pipelines, reducing stress and our own workload
- We used information radiators to inform others about what we were working on, reducing interruptions
- And we set clear priorities and weekly goals and followed up on them.

How it ended up working
Rather than hiring more people, in this case the crisis really allowed us to transform our way of working, reaching a state where we did way more with way less and being more effective, efficient and satisfied at the same time.
Conclusion
I want to conclude with a recap of the things I’ve written today. This is my experience and as this is a complex or at least complicated problem, your mileage will most likely vary.
- High workload leads to increasing waiting times
- Crisis situations are opportunities for change and often it takes fresh eyes or at least courage to see problems
- Get out of the quicksand with DevOps:
This is also in line with the Three Ways of DevOps
- The First Way: System Thinking / Flow
- The Second Way: Amplify Feedback Loops
- The Third Way: Culture of Continual Experimentation and Learning
And don’t forget that it is people over process over tools.
Further references and information
If you want to know more, you should really read these books, follow these links or watch the talks of the authors:
- Tom DeMarco - Slack
- Jez Humble, Joanne Molesky, Barry O’Reilly - Lean Enterprise
- Donald Reinertsen-The Principles of Product Development Flow: Second Generation Lean Product Development.
- Gene Kim, George Spafford, Kevin Behr -The Phoenix Project
- Gene Kim, Jez Humble, John Willis, Patrick Debois - DevOps Handbook
- Christina J. Hogan, Strata R. Chalup, Thomas A. Limoncelli -The practice of cloud system administration
- Gary Gruver - Starting and Scaling DevOps in the Enterprise
- Gary Gruver - A Practical Approach to Large-Scale Agile Development
- Mik Kersten - Project to Product
- Nicole Forsgren, Jez Humble and Gene Kim - Accelerate: The Science of Lean Software and Devops: Building and Scaling High Performing Technology Organizations
- Dominica DeGrandis - Making Work Visible - How to Unmask Capacity Killing WIP
- Betsy Beyer, Niall Richard Murphy, David K. Rensin, Kent Kawahara, Stephen Thorne - The Site Reliability Workbook
- Betsy Beyer, Chris Jones, Jennifer Petoff and Niall Richard Murphy - Site Reliability Engineering
- Eliyahu M. Goldratt - The Goal
- John Cutler - This feels like going faster vs. this actually makes us faster
- John Cutler – Slack vs. Blocked
- Gene Kim, John Willis - Beyond the Phoenix Project
Summary
I want to close with a quote:
We don’t let our servers get to 100% capacity utilization, so let’s not do that to ourselves
Outlook
After putting in countless hours eliminating waste, improving the deployment pipeline, investing in automation and deploying new technologies, it is time to ask this fundamental question: “Are we really moving faster?”
When measuring, you don’t have to stop at the mentioned DevOps metrics. This is where flow metrics and dashboards can help.
In from Project to Product Mik Kersten introduces the Flow Framework.
It proposes to track flow velocity, flow efficiency, flow time, flow load as well as flow distribution for features, defects, risks and technical debt. It is business outcome driven as it also recommends to track business value, cost, quality and team happiness (with a survey). Carmen DeArdo gives a great overview.
But that’s something for 2020. Stay tuned!
If you have any questions, recommendations, hints, or just want to say thanks, feel free to contact me. You can reach me on twitter @rompic or via mail at hello@pickl.eu
Thanks for reading this article.